基于opencv与机器学习的摄像头实时识别数字
前言
使用摄像头实时识别数字算是目标检测任务,总体上分为两步,第一步是检测到数字卡片的位置,第二步是对检测到的数字卡片进行分类以确定其是哪个数字。在第一步中主要涉及opencv的相关功能,第二步则使用机器学习的方式进行分类。
一、使用opencv捕捉(检测)数字卡片
重点操作是使用轮廓查找函数,获取数字卡片的外轮廓。
在获取轮廓前的图像预处理步骤需要根据自己的实际应用场景进行调整。
import cv2
import imutils
# 开启外接摄像头
cap = cv2.VideoCapture(1)
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (11, 11))
while True:
flag, frame = cap.read()
if frame is None:
continue
if flag is True:
frame_copy = frame.copy()
frame_copy_2 = frame.copy()
frame_copy_3 = frame.copy()
# 自动阈值处理
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame_ths = cv2.threshold(frame_gray, 0, 255, cv2.THRESH_BINARY_INV|cv2.THRESH_OTSU)[1]
# 闭操作
img_closed = cv2.morphologyEx(frame_ths, cv2.MORPH_CLOSE, rectKernel)
# canny边缘检测;这里使用的imutils包,也可以使用opencv自带的canny
temp = imutils.auto_canny(img_closed)
# 轮廓查找
contours, hierarchy = cv2.findContours(temp, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
# 计算轮廓
for index, c in enumerate(contours):
area = cv2.contourArea(c)
x, y, w, h = cv2.boundingRect(c)
# 通过判断轮廓的外接矩形面积确定数字卡片的轮廓,实现过滤功能
if area > 10000:
# img_out = cv2.drawContours(frame_copy, contours, index, (0, 0, 255), 2)
img_out = cv2.rectangle(frame_copy, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow("ths", frame_ths)
cv2.imshow("canny", temp)
cv2.imshow("closed", img_closed)
cv2.imshow("lun kuo", frame_copy)
if cv2.waitKey(1) & 0xFF == 27:
cap.release()
cv2.destroyAllWindows()
break
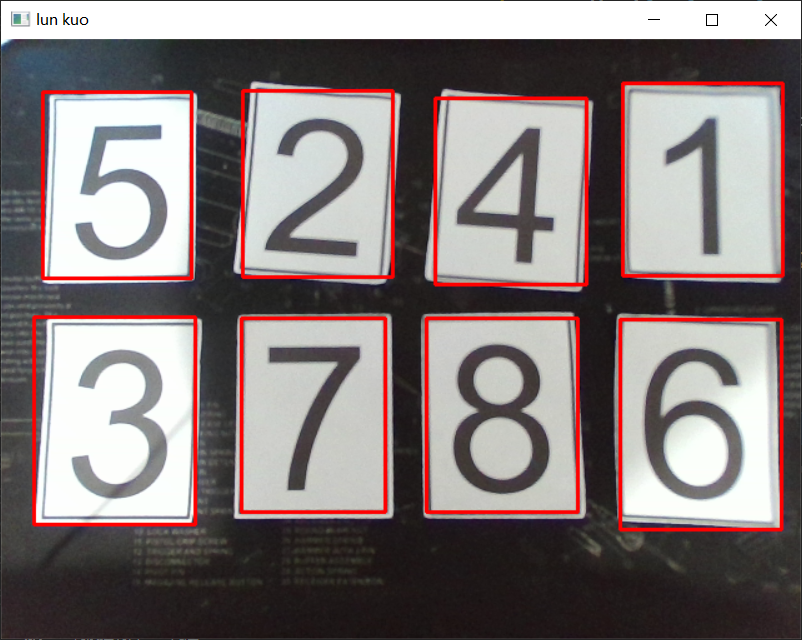
效果图如下:
二、制作数据集
在获取数字卡片轮廓的基础上,保存轮廓区域内的图片信息作为基础数据集。为了方便保存,可以使用pynput包完成键盘监控功能,按下一次回车即拍摄一张。
from pynput.keyboard import Key, Listener
import cv2
import imutils
# 按键获取数据集
global res_img
counts = 0 # 图片计数
def on_press(key):
global counts
# 回车触发
if key == Key.enter:
# 保存图片路径
cv2.imwrite(f"1/1_{counts}.png", res_img)
counts += 1
print(f"Save sucess {counts}")
# 开启键盘监听
listener = Listener(on_press=on_press)
listener.start()
cap = cv2.VideoCapture(1)
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (11, 11))
while True:
flag, frame = cap.read()
if frame is None:
continue
if flag is True:
frame_copy = frame.copy()
frame_copy_2 = frame.copy()
# 自动阈值处理
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame_ths = cv2.threshold(frame_gray, 0, 255, cv2.THRESH_BINARY_INV|cv2.THRESH_OTSU)[1]
# 闭操作
img_closed = cv2.morphologyEx(frame_ths, cv2.MORPH_CLOSE, rectKernel)
# canny边缘检测
temp = imutils.auto_canny(img_closed)
# 轮廓查找
contours, hierarchy = cv2.findContours(temp, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
# 计算轮廓
for index, c in enumerate(contours):
area = cv2.contourArea(c)
x, y, w, h = cv2.boundingRect(c)
if area > 10000:
img_out = cv2.rectangle(frame_copy, (x, y), (x + w, y + h), (0, 0, 255), 2)
# 获取轮廓区域的图像
res_img = frame_copy_2[y:y+h, x:x+w]
cv2.imshow("lun kuo", frame_copy)
if cv2.waitKey(1) & 0xFF == 27:
cap.release()
cv2.destroyAllWindows()
listener.stop()
break
每一个数字都要拍摄多张不同角度的图片,这个数据集的拍摄质量将影响最终识别的效果,所以拍摄时需要考虑实际的应用场景。
保存后的图片应该如下图所示。

拍摄完之后,最好再对数据集进行数据增强,以扩充数据集,提高模型的训练效果。
使用albumentations包进行数据增强,其具体的使用方式可以去Albumentations Documentation查看。
import albumentations as A
import cv2
import os
# 设置需要使用的数据增强方式
transform = A.Compose([
A.Resize(height=128, width=128), # 图片缩放
A.Rotate(limit=[-70, 70], p=0.5), # 随机旋转
A.RandomBrightnessContrast(p=0.3), # 随机亮度对比度
])
# 遍历每一个数字文件夹
for i in range(1, 9):
# 图片计数
counts = 0
img_list = os.listdir(f"data/{i}")
for temp in img_list:
image = cv2.imread(f"data/{i}/{temp}")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
transformed = transform(image=image)['image']
# 保存数据增强后的图片
cv2.imwrite(f"data/{i}/{i}_{counts}.png", transformed)
counts += 1在数据增强后,每个数字的数据集为220张。
三、使用sklearn建立机器学习模型实现数字分类
常用的机器学习分类模型有KNN和SVM等,可以都试一下,选择效果最好的一个。
首先需要对数据集进行预处理
import cv2
import os
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
import joblib
X_img = [] # 用于存放图片信息
y_img = [] # 用于存放标签(label)信息
# 遍历加载数据集
for i in range(1, 9):
img_list = os.listdir(f"data/{i}")
for temp in img_list:
image = cv2.imread(f"data/{i}/{temp}")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.resize(image, (128, 128))
X_img.append(image)
y_img.append(i)
# 转换成二维数组 (1758, 128, 128) ==> (1758, 16384)
X_img = np.array(X_img).reshape(len(X_img), -1)
y_img = np.array(y_img)
print(X_img.shape)
print(y_img.shape)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_img, y_img, test_size=0.2)
# PCA降维 可以降低计算量,提高训练速度,减小模型大小
transfer = PCA(n_components=300)
X_train = transfer.fit_transform(X_train)
X_test = transfer.transform(X_test)
print(X_train.shape)
print(X_test.shape)
# 保存PCA降维信息,后续在实时预测时会使用到该信息
joblib.dump(transfer, 'pca_model.joblib')
之后建立SVM分类模型并进行训练和测试。
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 建立svm分类器
svm = SVC(kernel='linear')
# 使用训练数据来训练SVM分类器
svm.fit(X_train, y_train)
# 使用测试数据进行预测
y_pred = svm.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
# 最终准确率为0.9573863636363636
print("Accuracy:", accuracy)
# 保存训练好的模型
joblib.dump(svm, 'svm_model_PCA300.joblib')最后进行单张图片预测,查看预测效果。
import joblib
import cv2
# 加载SVM分类模型
loaded_svm = joblib.load('svm_model_PCA300.joblib')
# 加载PCA降维模型
loaded_pca = joblib.load('pca_model.joblib')
# 读取图片并进行预处理
img = cv2.imread("data/4/4_39.png")
img = cv2.resize(img, (128, 128))
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
temp = img.reshape(1, -1)
# PCA降维,保证格式与训练数据相同
temp = loaded_pca.transform(temp)
print(temp.shape)
y_new_pred = loaded_svm.predict(temp)
# 输出预测结果
print("Predictions for new data:", y_new_pred)四、摄像头实时预测
将前面的部分结合起来就可以实现摄像头实时预测的任务了。
import cv2
import imutils
from pynput.keyboard import Key, Listener
import joblib
# 加载SVM和PCA模型
loaded_svm = joblib.load('svm_model_PCA300.joblib')
loaded_pca = joblib.load('pca_model.joblib')
# 显示字体配置
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1
font_thickness = 2
color = (0, 255, 0)
cap = cv2.VideoCapture(1)
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (11, 11))
while True:
flag, frame = cap.read()
if frame is None:
continue
if flag is True:
frame_copy = frame.copy()
frame_copy_2 = frame.copy()
# 自动阈值处理
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame_ths = cv2.threshold(frame_gray, 0, 255, cv2.THRESH_BINARY_INV|cv2.THRESH_OTSU)[1]
# 闭操作
img_closed = cv2.morphologyEx(frame_ths, cv2.MORPH_CLOSE, rectKernel)
# canny边缘检测
temp = imutils.auto_canny(img_closed)
# 轮廓查找
contours, hierarchy = cv2.findContours(temp, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
# 计算轮廓
for index, c in enumerate(contours):
area = cv2.contourArea(c)
x, y, w, h = cv2.boundingRect(c)
if area > 10000:
img_out = cv2.rectangle(frame_copy, (x, y), (x + w, y + h), (0, 0, 255), 2)
res_img = frame_copy_2[y:y+h, x:x+w]
# 图像预处理
img = cv2.resize(res_img, (128, 128))
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
temp = img.reshape(1, -1)
# PCA降维
temp = loaded_pca.transform(temp)
y_new_pred = loaded_svm.predict(temp)
cv2.putText(frame_copy, f"Pred: {y_new_pred}", (int(x), int(y)),
font, font_scale, color, font_thickness)
cv2.imshow("lun kuo", frame_copy)
if cv2.waitKey(1) & 0xFF == 27:
cap.release()
cv2.destroyAllWindows()
break


